MeshfreeFlowNet: A Physics-Constrained Deep Continuous Space-Time Super-Resolution Framework
Chiyu "Max" Jiang*1 Soheil Esmaeilzadeh*2 Kamyar Azizzadenesheli3Karthik Kashinath4 Mustafa Mustafa4 Hamdi Tchelepi2 Philip Marcus1 Prabhat4
Anima Anandkumar5,6
(* Denotes Equal Contributions)
1 University of California, Berkeley 2 Stanford University 3 Purdue University
4 Lawrence Berkeley National Lab 5 California Institute of Technology 6 NVIDIA
Published at International Conference for High Performance Computing, Networking, Storage and Analysis (SC20). Best Student Paper Award Finalist.
[Paper] [Code] [Bibtex] [Video]
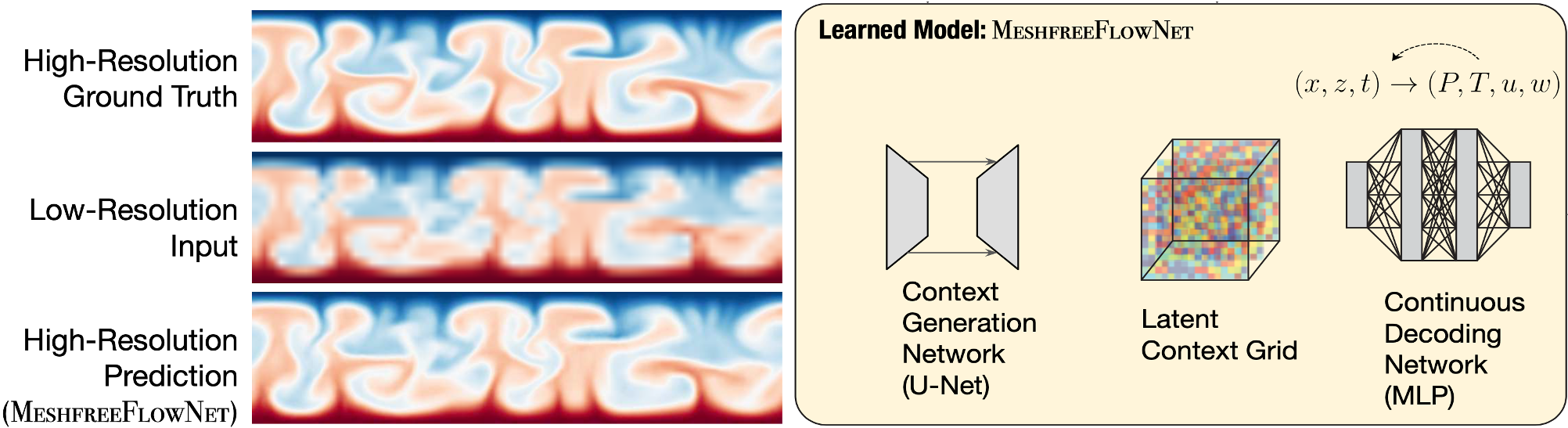
Figure 1 MeshfreeFlowNet is a novel deep learning-based super-resolution framework to generate continuous (grid-free) spatio-temporal solutions from the low-resolution inputs. It consists of two end-to-end trainable modules, the Context Generation Network, and a Continuous Decoding Network.
Abstract
We propose MeshfreeFlowNet, a novel deep learning-based super-resolution framework to generate continuous (grid-free) spatio-temporal solutions from the low-resolution inputs. While being computationally efficient, MeshfreeFlowNet accurately recovers the fine-scale quantities of interest. MeshfreeFlowNet allows for: (i) the output to be sampled at all spatio-temporal resolutions, (ii) a set of Partial Differential Equation (PDE) constraints to be imposed, and (iii) training on fixed-size inputs on arbitrarily sized spatio-temporal domains owing to its fully convolutional encoder.
We empirically study the performance of MeshfreeFlowNet on the task of super-resolution of turbulent flows in the Rayleigh–Bénard convection problem. Across a diverse set of evaluation metrics, we show that MeshfreeFlowNet significantly outperforms existing baselines. Furthermore, we provide a large scale implementation of MeshfreeFlowNet and show that it efficiently scales across large clusters, achieving 96.80% scaling efficiency on up to 128 GPUs and a training time of less than 4 minutes.
Gallery
Figure 2 Visualization of the super-resolution quality of the MeshfreeFlowNet. The framerate is limitted for the gif animation. For better results, checkout the video link above.